



Evaluation Metrics For Regression Problems
Evaluation (Performance) Metrics For Machine Learning Regression Problems


In a previous article titled Evaluating Machine Learning Algorithms, I discussed evaluation methods, which estimate how well a given machine learning algorithm will perform at making predictions about unseen data. Example evaluation methods include train-test splitting, k-fold cross-validation, and leave one out cross-validation.
Whereas evaluation methods estimate a model's performance on unseen data, evaluation metrics are the statistical techniques employed to quantify how well the model works. Thus, to evaluate a machine learning algorithm, we must select an evaluation method and evaluation metric(s).
In this article, I will focus on a regression problem, using information about a medical patient’s age, sex, BMI, number of dependents, smoking status, and residential area within the United States to predict their individual medical costs billed by health insurance. 1
If you’re interested in learning about evaluation metrics for classification problems you can check out my previous article titled Evaluation Metrics For Classification Problems.
Additionally, in all of the code examples, I will use the same algorithm (linear regression) and evaluation method (k-fold cross-validation) while demonstrating the following regression metrics:
The mean absolute error (MAE), which is the average of the sum of absolute errors in predicted values;
The root Mean squared error (RMSE), which is the square root of the mean of squared differences between actual and predicted outcomes; and
R², also known as the coefficient of determination, which is provides an indication of the goodness of fit of a set of predictions as compared to the actual values.
Mean Absolute Error (MAE):
Regression is a data analysis technique that uses a known data point to predict a single unknown but related data point—for example, predicting someone's relative risk of stroke based on their systolic blood pressure.
The mean absolute error (MAE) is an easy way to determine how wrong your predictions are when solving regression problems. Specifically, the MAE quantifies the error in your predicted values versus the actual, expected values.
The mean absolute error is defined as the average of the sum of absolute errors. The term 'absolute' conveys that the error values are made positive, so they can be added to determine the magnitude of error. Thus, one limitation of MAE is that there is no directionality to the errors, so we don't know if we're over or underpredicting.
The formula for mean absolute error (MAE) is as follows:

Below you'll find sample code calculating the mean average error of medical insurance cost predictions using a simple linear regression model to make predictions and k-fold cross-validation as an evaluation method:

Which produces the following output:

You’ll notice that the mean absolute error is negative, which is due to the metric being inverted by the cross_val_score( ) function.
Root Mean Squared Error (RMSE):
The root mean squared error (RMSE) is one of the most commonly used evaluation metrics for regression problems.
RMSE is the square root of the mean of squared differences between actual and predicted outcomes. Squaring each error forces the values to be positive. Calculating the square root of the mean squared error (MSE) returns the evaluation metric to the original units, which is useful for presentation and comparison.
The formula for root mean squared error (RMSE) is as follows:
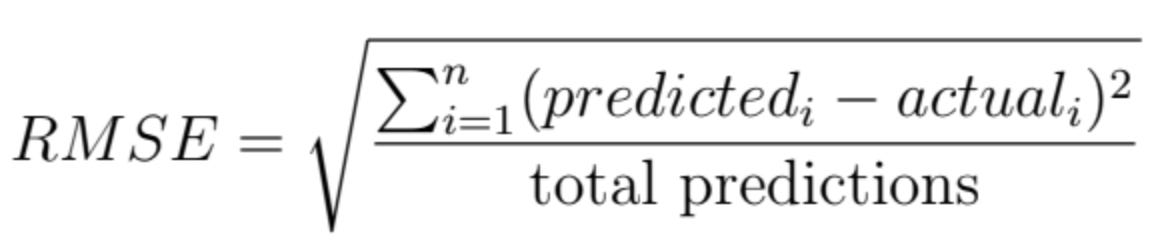
Below you'll find sample code calculating the RMSE of medical insurance cost predictions:

Which results in the following output:

The above examples show that the RMSE (6098) is slightly larger than the MAE (4204). RMSE values are always higher than MAE values because RMSE penalizes larger errors with worse scores. Thus, the difference between RMSE and MAE scores increases as prediction errors increase, which is the primary advantage of using RMSE as an evaluation metric.
R² (R Squared):
The R², also known as the coefficient of determination, is an evaluation metric that provides an indication of the goodness of fit of a set of predictions as compared to the actual values.
The R² metric is scored from 0 to 1, where 1 is a perfect score and 0 means the predictions are entirely random and arbitrary.
Below you'll find sample code calculating the R² of medical insurance cost predictions:

Which produced the following output:

Data Source: Medical Cost Personal Dataset