



Evaluating Machine Learning Algorithms
An Introduction To Resampling Methods For Evaluating ML Models

Why Evaluate Machine Learning Models?
Before deploying a machine learning model, the model needs to be evaluated on previously unseen data; otherwise, you may run the risk of overfitting.
Overfitting refers to a machine learning model so highly tuned to making predictions about the data it was trained on that it cannot make accurate predictions about new, unseen data. Overfitting is similar to when a student memorizes their class notes and answers to practice quizzes verbatim but fails on an actual exam with never before seen questions.
To avoid overfitting and make sure that our machine learning algorithms perfect well in practice, we must evaluate our models before deployment, which can be accomplished in two different ways:
You can train your model on one dataset, then have your model make predictions about a second, previously unseen, dataset in which you know the answers and can determine whether your model is making accurate predictions; or
You can use resampling techniques on a given dataset, which allows you to estimate how well your algorithm will perform on new data.
Both methods for evaluating the models above estimate how well your algorithm will perform on new unseen data, but they are not guaranteed. Additionally, after evaluating a model, we often want to re-train it and perform another round of evaluations before deployment to ensure optimal performance.
In this article, i’ll cover the following methods for evaluating machine learning models:1
Train-test split is simple evaluation method that splits your dataset into two parts, including a training set (used to train your model) and a testing set (used to evaluate your model).
k-fold cross-validation is an evaluation technique that splits your dataset into k-parts to estimate the performance of a machine learning model with greater reliability than a single train-test split; and
Leave one out cross-validation is a form of k-fold cross-validation, but taken to the extreme where k is equal to the number of samples in your dataset.
Train-Test Split
The train-test split evaluation technique involves taking your original dataset and splitting it into two parts - a training set used to train your machine learning model and a a testing set used to evaluate your model.
After splitting your dataset you can train your model on the first partition of the dataset (i.e., the train split) and then evaluate your model by making predictions about the second partition of the dataset (i.e., the test split). The relative size of the train and test splits can vary, but in general 65-75% of your dataset should be used for training while the remaining 25-35% is used for evaluation.
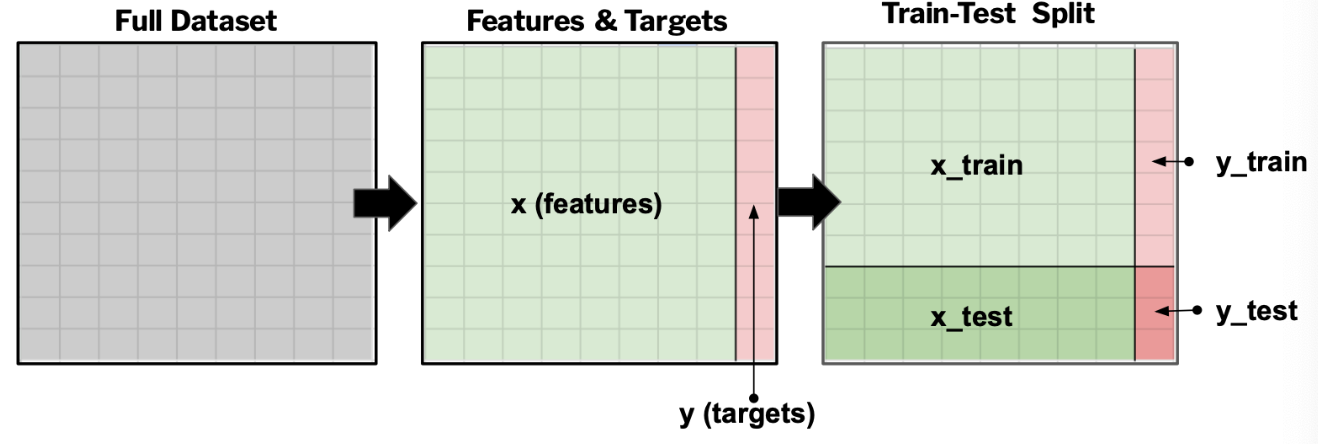
The main benefit of a train-test split is its fast and easy use. However, for it to be effective, you need a large dataset. Additionally, the dataset needs to be relatively homogenous such that both splits of the dataset are representative of the whole sample.
Below you’ll find sample code performing a train-test split on the Pima Diabetes Dataset:

The accuracy for this specific configuration is 77.32%. However, adjusting both the test_split size (which is currently set to 35%) and the random seed (currently set to 5) alter this score by +/- ~2%.
k-fold Cross-validation
k-fold cross-validation is an evaluation technique that estimates the performance of a machine learning model with greater reliability (i.e., less variance) than a single train-test split.
k-fold cross-validation works by splitting a dataset into k-parts, where k represents the number of splits, or folds, in the dataset. When using k-fold cross-validation, your machine learning model is trained on k-1 folds. For example, if k=10, ten folds are created, with nine of them used to train your model and one for testing.
What makes k-fold cross-validation so powerful is that each of your folds is held back and used for testing once. So, for example, if k=4, then you evaluate your model four times, and each time a different fold is used for testing while the other three are used to train your model, as demonstrated in the image below. This results in four performance scores, which can be averaged to determine how well your model performs.
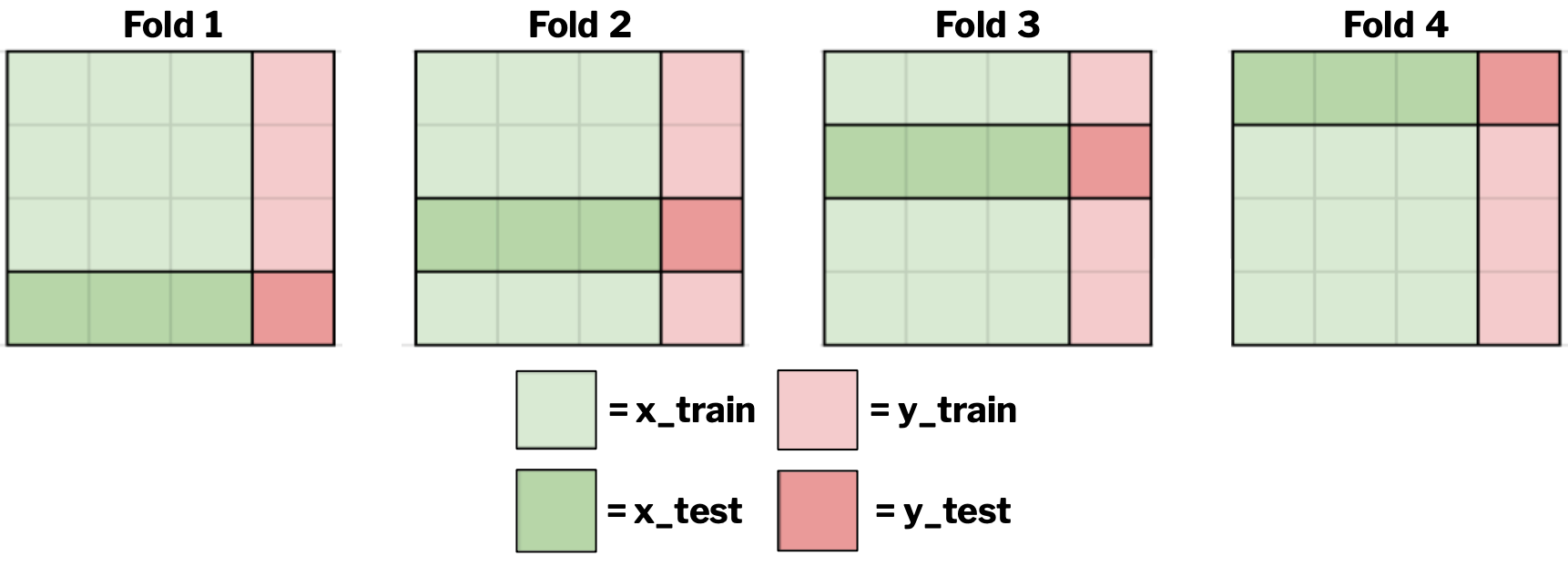
When performing k-fold cross-validation, the most critical decision you'll have to make is how large your k is (i.e., how many splits or folds you create). For moderate-sized datasets (thousands or tens of thousands of rows), k-values of 5-10 are common, whereas k-values of 3-5 are more appropriate for smaller datasets.
Below you’ll find sample code performing a k-fold cross-validation on the Pima Diabetes Dataset:

Which results in the following outputs:

You’ll notice that the above code outputs individual performance scores of each of the five splits, the mean result, and the standard deviation of the results. The smaller the standard deviation, the more consistent and reliable the results are.
Leave One Out Cross-Validation:
Leave one out cross-validation is a form of k-fold cross-validation, but taken to the extreme where k is equal to the number of samples in your dataset. For example, if you have one-hundred rows of data k=100 (i.e., there are 100 folds). Therefore, every time the model is evaluated, 99 folds will be used to train the model, and one fold will be used for testing. This process is repeated until each of the 100 folds has been 'left out' and used to evaluate the model.
The advantage of leave one out cross-validation is that it provides a very accurate and reliable estimate of a machine learning model's performance. However, the downside of leave one out cross-validation is that it's very computationally expensive to run. As a result, it should only be used with small datasets or when accuracy is of the utmost importance (as is often the case in medicine).
Below you'll find a sample code performing leave one out cross-validation on the Pima Diabetes Dataset:

Which results in the following outputs:

As you can see, the mean result for leave one out cross-validation is similar to k-fold cross-validation, though they vary from each other by ~1%. However, we can assume the mean result from leave one out cross-validation is a more reliable estimate of our model's performance. You’ll also notice that the standard deviation is much larger for leave one out cross-validation compared to k-fold cross-validation. The reason for this is that the training sets in leave one out cross-validation have more overlap, which is explained further in section 7.10.1 in The Elements of Statistical Learning quoted below:
“What value should we choose for 𝐾? With 𝐾=𝑁, the cross-validation estimator is approximately unbiased for the true (expected) prediction error, but can have high variance because the 𝑁 "training sets" are so similar to one another.” -Hastie et al.
Practical Implementation:
Thus far, we’ve covered the following methods for evaluating machine learning models: train-test split, k-fold cross-validation, and leave one out cross-validation. Now, it’s time to review some heuristics for selecting an evaluation method.
I first recommend deciding whether you’re more concerned with speed or reliability. If speed is your priority, then a train-test split is often a good choice for evaluating models, so long as the dataset is relatively homogenous. On the other hand, if accuracy and reliability are of the utmost importance, then leave one out cross-validation is a good choice as long as your dataset is small to medium size (remember, leave one out cross-validation is very computationally expensive and thus relatively slow with large datasets).
Remember, we rarely care just about speed or reliability; in most cases, we want a balance of the two. k-fold cross-validation is useful for this reason, as it’s both fast and provides accurate results. In fact, k-fold cross-validation (with a k of 3-10) is considered by some to be the gold standard method for evaluating machine learning models due to its versatility and ease of implementation.
All of the code examples in this article use the Pima Diabetes Dataset, which originates from the National Institute of Diabetes and Digestive Kidney Disease. The original purpose of this dataset was to use certain diagnostic measurements to predict whether or not a patient has diabetes.