



Comparing Machine Learning Models
Algorithm Spot-Checking For Classification And Regression Problems


Comparing Machine Learning Algorithms:
For any machine learning problem, we must select an algorithm to make predictions, an evaluation method to estimate a model's performance on unseen data, and an evaluation metric(s) to quantify how well the model works.
Unfortunately, we can't always know which algorithm will work best on our dataset beforehand. As a result, we have to try several algorithms, then focus our attention on those that seem most promising. Thus, it's important to have quick and easy ways to assess and compare different algorithms' performance before we select one to tune and optimize - this is where spot-checking comes in.
Spot-checking is a way to quickly discover which algorithms perform well on your machine-learning problem before selecting one to commit to. Generally, I recommend that you spot-check five to ten different algorithms using the same evaluation method and evaluation metric to compare the model's performance.
In this article, I will use k-fold cross-validation1 as my evaluation method, with classification accuracy2 as my evaluation metric for classification problems and mean squared error (MSE)3 as my evaluation metric for regression problems.
Often you'll notice that a few of your spot-checked algorithms perform much better than the rest. I recommend selecting two to three models with the best performance, then double down and spend time tuning those algorithms to make your predictions increasingly accurate.
Algorithm Spot-Checking For Classification Problems:
A classification problem in machine learning is one in which a class label is predicted given specific examples of input data.
In this article, I will use the Pima Diabetes dataset for my demonstration. The Pima Diabetes dataset is a binary classification problem with two numerical output classes (0 = no diabetes and 1 = diabetes).
The key to fairly comparing different spot-checked machine learning algorithms is to evaluate each algorithm in the same way, which is achieved with a standardized test harness. In this article, each algorithm we spot-check will be used to predict whether a given patient has diabetes, using k-fold cross-validation and classification accuracy as our evaluation method and evaluation metric, respectively.
Finally, we will spot-check the following six algorithms:
Logistic regression, which is a data analysis technique that uses several known input values to predict a single unknown data point;
Linear discriminant analysis (LDA), which makes predictions for both binary and multi-class classification problems;
k-nearest neighbors (KNN), which finds the k most similar training data points for a new instance and takes the mean of the selected training data points to make a prediction;
Naive bayes (NB), which calculates the probability and conditional probability of each class, given each input value, and then estimates these probabilities for new data;
Classification and regression trees (CART), which construct binary tress from the training data and generate splits to minimize a cost function; and
Support vector machine (SVM), which seek a line that best separates to classes based on the position of various support vectors.
Below you’ll find sample code spot-checking the six algorithms above and generating a box plot to compare the results:

Which produces the following output:
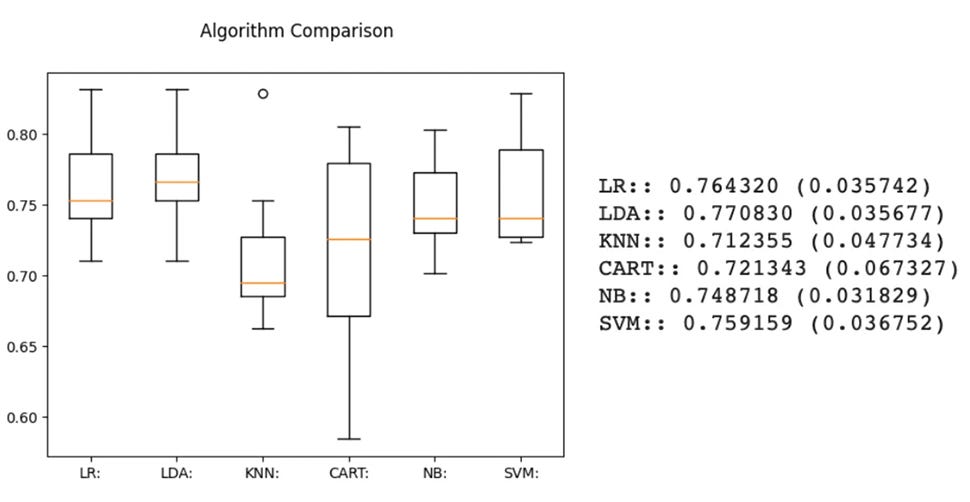
Based on these results we can see that linear discriminant analysis (LDA) and logistic regression (LR) produce the best results. Thus, these two algorithms can be selected for tuning and optimization to enhance their ability to make accurate predictions.
Algorithm Spot-Checking For Regression Problems:
A regression problem in machine learning is one in which a single unknown data point is predicted from related known data points. For example, in this article, I will spot-check a series of algorithms used to predict an individual’s medical costs billed by health insurance using information about the patient’s age, sex, BMI, number of dependents, smoking status, and residential area within the United States.
The six following algorithms will be spot-checked:
Linear regression4, which is a data analysis technique that assumes a linear relationship between known inputs and predicted outputs;
Ridge regression, which is a modified version of linear regression that, is best used when the independent variables in the data are highly correlated;
LASSO regression, which is also a modified version of linear regression where the model is penalized for the sum of absolute values of the weights;
ElasticNet regression, which is a regularized form of regression that combines the characteristics of both ridge and LASSO regression;
k-nearest neighbors (KNN), which finds the k most similar training data points for a new instance and takes the mean of the selected training data points to make a prediction;
Classification and regression trees (CART), which construct regression trees from the training data and generate splits to minimize a cost function (in this case, MSE); and
Support vector machine for regression (SVR), which is an extension of SVM for binary classification that has been modified to predict continuous numerical outputs.
Below you’ll find sample code spot-checking the six algorithms above and generating a box plot to compare the results:

Which produces the following output:

Based on these results we can see that LASSO, ridge, and linear regression produce the best results. Thus, these three algorithms can be selected for tuning and optimization to enhance their ability to make accurate predictions.
Closing Thoughts:
In this article you learned how to spot-check algorithms with a standardized test harness, then compare the results to determine which algorithms to select for tuning and optimization.
You can use the code in this article as a template for evaluating algorithms for your own classification and regression problems.
👉 If you have any questions about the content in this article please let me know in the comment section below.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack. The button is located towards the bottom of this email.
👉 If you enjoy reading this newsletter, please share it with friends!
To learn more about k-fold cross-validation check out my article titled, Evaluating Machine Learning Algorithms.
To learn more about classification accuracy, and other classification metrics, check out my article titled, Evaluation Metrics For Classification Problems.
To learn more about mean squared error, and other regression metrics, check out my article titled, Evaluation Metrics For Regression Problems.
To learn more about linear regression you can read my article titled, Making Predictions With Simple Linear Regression.