



An Introduction To Hyperparameter Optimization
Tuning Machine Learning Algorithms To Optimize Performance


What Are Hyperparameters?
You can think of machine learning algorithms as systems with various knobs and dials, which you can adjust in any number of ways to change how output data (predictions) are generated from input data. The knobs and dials in these systems can be subdivided into parameters and hyperparameters.
Parameters are model settings that are learned, adjusted, and optimized automatically. Conversely, hyperparameters need to be manually set manually by whoever is programming the machine learning algorithm.
Generally, tuning hyperparameters has known effects on machine learning algorithms. However, it’s not always clear how to best set a hyperparameter to optimize model performance for a specific dataset. As a result, search strategies are often used to find optimal hyperparameter configurations. In this newsletter, I’m going to cover the following hyperparameter tuning methods:
Grid Search is a cross-validation technique for hyperparameter tuning that finds an optimal parameter value among a given set of parameters specified in a grid; and
Random Search is a tuning technique that randomly samples a specified number of uniformly distributed algorithm parameters.
Where Does Hyperparameter Tuning Fit In The Big Picture?
Before I show you how to use grid search and random search, you need to understand where these processes, or hyperparameter tuning more broadly, fit in the grand scheme of creating and deploying machine learning models.
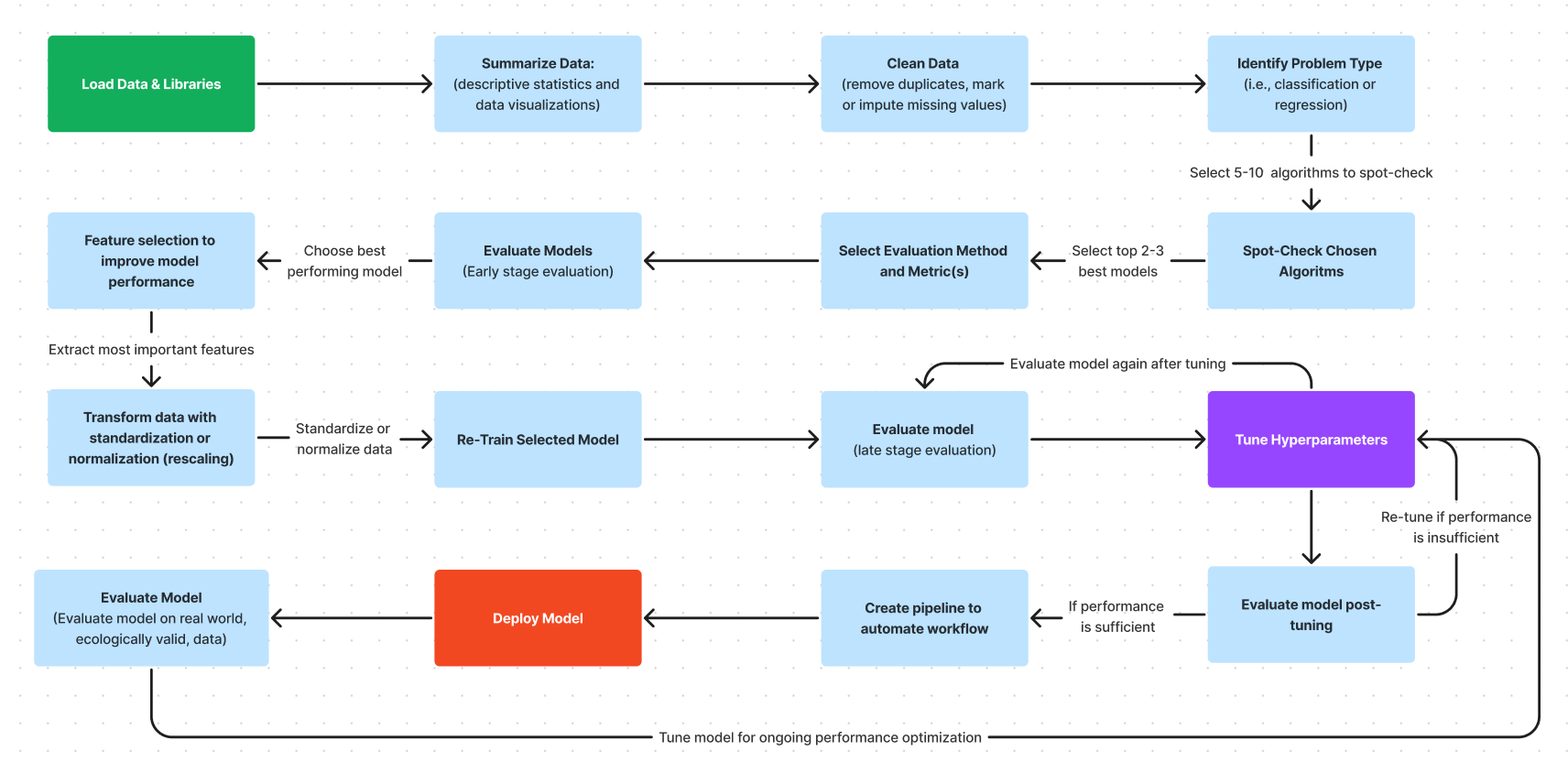
The image below visually represents the varying steps between identifying what type of machine learning problem you’re working with and deploying a functioning machine learning model that makes accurate predictions on unseen data.
You can see that hyperparameter tuning is one of the final steps before you create a pipeline to automate your workflow and deploy your model, as demonstrated below:
Hyperparameter Tuning With Grid Search:
Grid Search is a cross-validation technique for hyperparameter tuning that finds an optimal parameter value among a given set of parameters specified in a grid.
In a previous newsletter, Comparing Machine Learning Algorithms, I spot-checked several different algorithms and compared their performance in predicting whether a patient has diabetes using the Pima Diabetes dataset. After spot-checking six different algorithms, I found that logistic regression and linear discriminant analysis (LDA) produced the best results. I then suggested that these algorithms be selected for tuning and optimization to enhance their ability to make accurate predictions.
In the code sample below, I will perform grid search hyperparamter tuning to evaluate different solvers, penalties, and penalty strengths to see if we can improve the aforementioned logistic regression models performance:
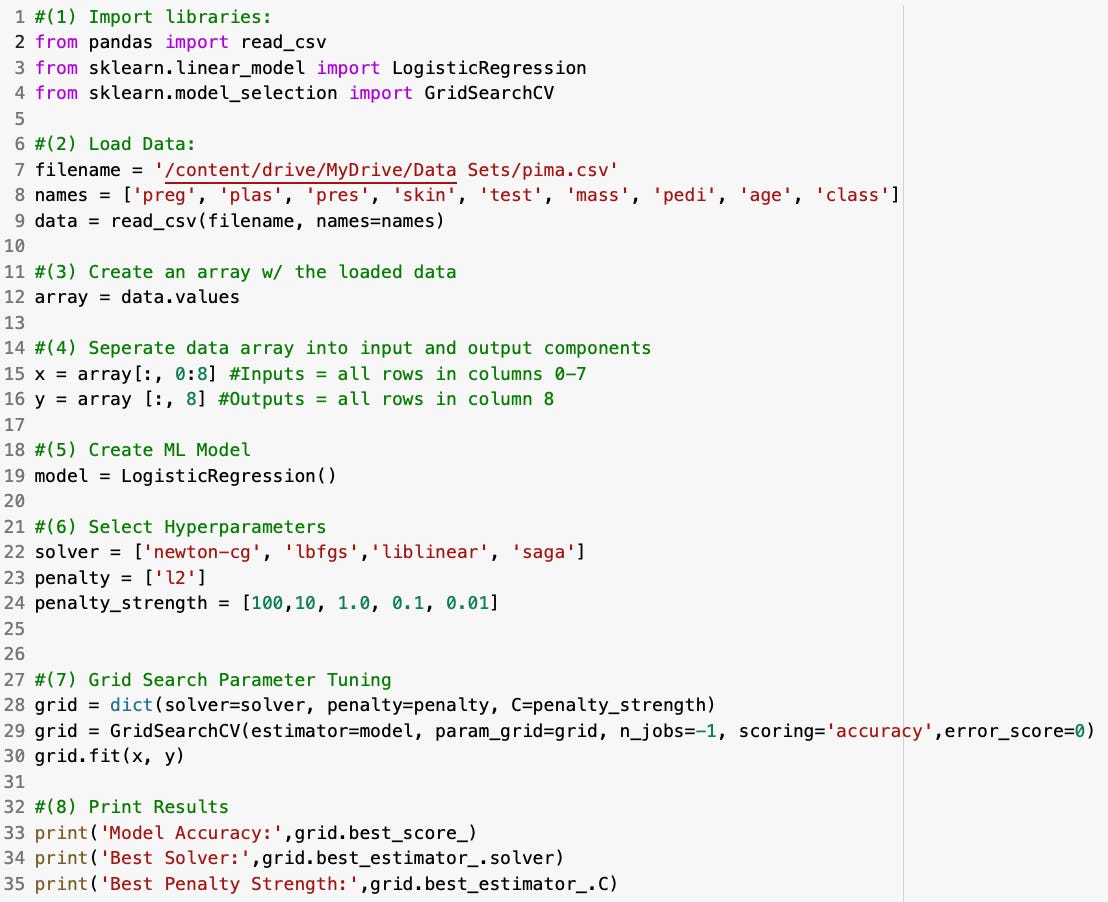
Which produces the following outputs:

In my previous newsletter, Comparing Machine Learning Algorithms, logistic regression produced an accuracy score of 0.764. Thus hyperparameter tuning boosted our accuracy by 0.8% (since the model performance was already good, hyperparameter tuning did not result in a substantial change in accuracy).
Hyperparameter Tuning With Random Search:
Random Search is a hyperparameter tuning technique that randomly samples a specified number of uniformly distributed algorithm parameters.
In the code sample below, I will perform random search hyperparamter tuning to evaluate different solvers, penalties, and penalty strengths to see if we can improve the aforementioned logistic regression models performance:

Which produces the following outputs:

As previously mentioned, the baseline performance for our logistic regression model was 76.4%, and the model’s performance after grid search hyperparameter tuning was 77.2% (0.8% improvement from baseline). For comparison, we can see that random search produced a 1% improvement above baseline and a 0.2% improvement above grid search.
👉 If you have any questions about the content in this newsletter please let me know in the comment section below.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack. The button is located towards the bottom of this email.
👉 If you enjoy reading this newsletter, please share it with friends!